I ran into an interesting scenario the other day while adding the new auto-incrementing Ids feature to OSCADSharp.
What does the feature entail? Simply put, anytime someone instantiates an object in OSCADSharp or performs an operation that adds more nodes to the object tree you're working on, each object should have its own unique auto-incrementing Id. (Eg. 1, 2, 3, 4...)
Pretty straightforward right? The naive implementation was very simple, as you might expect.
What does the feature entail? Simply put, anytime someone instantiates an object in OSCADSharp or performs an operation that adds more nodes to the object tree you're working on, each object should have its own unique auto-incrementing Id. (Eg. 1, 2, 3, 4...)
Pretty straightforward right? The naive implementation was very simple, as you might expect.
Id Generator Non-Threadsafe Version:
Not much to it.... But there's a big catch:
I knew this implementation isn't guaranteed to produce unique Ids in a scenario where multiple threads are instantiating objects that need unique Ids... So I wanted to prove that this implementation isn't thread-safe before fixing it, by writing a unit test that demonstrates duplicate Ids will be created when multiple threads are creating objects in parallel.
The initial test:
I knew this implementation isn't guaranteed to produce unique Ids in a scenario where multiple threads are instantiating objects that need unique Ids... So I wanted to prove that this implementation isn't thread-safe before fixing it, by writing a unit test that demonstrates duplicate Ids will be created when multiple threads are creating objects in parallel.
The initial test:
Parallel Ids Unit Test
Obviously this unit test isn't as straightforward as it looks, so let me explain a few components:
ConcurrentBag:
ConcurrentBag is a collection from the .NET parallel library. This is an thread-safe unordered collection designed to allow multiple threads to manipulate the collection.
Parallel.For:
Parallel.For is a .NET helper method with [TONS] of overloads, whose basic function is to break a for loop's iterations onto multiple threads. It can be a really convenient way of executing work in parallel, and there's more: Parallel.For dynamically decides how many threads to use, and automatically rejoins the child threads back to the parent tread after the work is completed. This way code that occurs on the lines below your Parallel.For block will still be executed next, after all that parallel work is complete. Pretty sick huh?
The catch here is that the 'magic' of Parallel.For means we can't easily predict what it will actually do in this situation... Which led me to a surprise result:
ConcurrentBag:
ConcurrentBag is a collection from the .NET parallel library. This is an thread-safe unordered collection designed to allow multiple threads to manipulate the collection.
Parallel.For:
Parallel.For is a .NET helper method with [TONS] of overloads, whose basic function is to break a for loop's iterations onto multiple threads. It can be a really convenient way of executing work in parallel, and there's more: Parallel.For dynamically decides how many threads to use, and automatically rejoins the child threads back to the parent tread after the work is completed. This way code that occurs on the lines below your Parallel.For block will still be executed next, after all that parallel work is complete. Pretty sick huh?
The catch here is that the 'magic' of Parallel.For means we can't easily predict what it will actually do in this situation... Which led me to a surprise result:

It passed?!? I ran the test 10 more times with the same result.
Why? The contributing factors were the number of threads (which would be low), and one another thing that's an important concept in parallelism:
Atomicity
An atomic operation in programming is an operation that can be executed in one CPU instruction. Because atomic operations are executed in one instruction, there is no intermediate state wherein competing threads would encounter incorrect data.
My Id generator is not atomic, but the most important step (globalId++) occurs in two CPU instructions, making the timing less-likely to be interrupted.
On the premise that there just aren't enough competing threads, and therefore not enough opportunities to create a scenarios where identical Ids are formed, I increased the number of iterations in my Parallel.For loop to 1000, and ran it again...
Why? The contributing factors were the number of threads (which would be low), and one another thing that's an important concept in parallelism:
Atomicity
An atomic operation in programming is an operation that can be executed in one CPU instruction. Because atomic operations are executed in one instruction, there is no intermediate state wherein competing threads would encounter incorrect data.
My Id generator is not atomic, but the most important step (globalId++) occurs in two CPU instructions, making the timing less-likely to be interrupted.
On the premise that there just aren't enough competing threads, and therefore not enough opportunities to create a scenarios where identical Ids are formed, I increased the number of iterations in my Parallel.For loop to 1000, and ran it again...
New Parallel.For
The result:
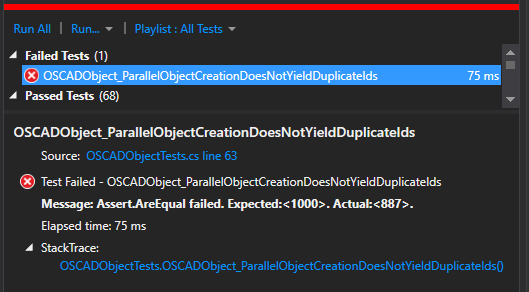
Not surprisingly the test fails now, and we have over 100 duplicate Ids. Yikes! The Id generator is thread-unsafe in a huge way.
Now that we've confirmed the concurrency issue let's move on to fixing my Id generator. I'm going to fix it by adding a Mutex. A mutex is a synchronization construct that prevents more than one thread from accessing a shared resource by using a key to control entry to code that utilizes a resource.
Here is my updated code, note that in C# the lock keyword provides a simple mutex:
Now that we've confirmed the concurrency issue let's move on to fixing my Id generator. I'm going to fix it by adding a Mutex. A mutex is a synchronization construct that prevents more than one thread from accessing a shared resource by using a key to control entry to code that utilizes a resource.
Here is my updated code, note that in C# the lock keyword provides a simple mutex:
Id Generator Threadsafe Version
See the difference? Multiple threads are prevented from simultaneously executing the body of the method, preventing duplicate Ids from being granted. With the lock statement in place, the globalId counter is guaranteed to have incremented/assigned back to the counter, then returned a value before the next thread is admitted into the block of code in our Get() method..
But did our unit test pass? You bet it did! Across many runs, and even if I increment my Parallel.For iteration count to 100,000. We effectively solved the concurrency issue with a simple lock statement.
But did our unit test pass? You bet it did! Across many runs, and even if I increment my Parallel.For iteration count to 100,000. We effectively solved the concurrency issue with a simple lock statement.

Food for thought... But you might be wondering if it was worth the effort?
Who cares?
To be honest, my original Id generator class would have sufficed for most purposes, but because OSCADSharp is a library that could be used by anyone, I can't guarantee that someday someone won't try to do a bunch of parallel work with it and get bitten by duplicate Ids.
Although in general you won't need to prematurely prepare for concurrency-related issues, there are situations where preventing concurrency issues can indirectly save your team (or API users) a LOT of suffering. Trust me.
So if you can spend a small amount of effort to prevent some lost sleep for some poor programmer who comes after you, by all means do so!
 RSS Feed
RSS Feed